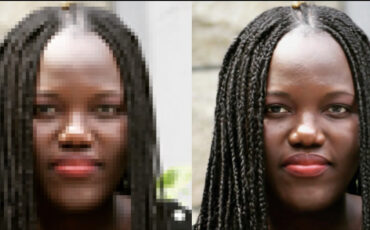昨年から、テキスト、画像、動画を生成する人工知能(AI)モデルが飛躍的に発展している。あまりの速さに、ついていくのが大変なほどだ。高速なスタートアップに比べ、グーグルのようなハイテク大手は、この道をゆっくりと、慎重に進むことを決めている。とはいえ、彼らの研究成果も目を見張るものがある。そのひとつは、グーグルのAIでテキストから高解像度のムービーを作成することを約束している。
グーグルの新しいディープラーニングモデルを使えば、ユーザーはテキスト入力だけで、高画質の動画を生成できるようになるはずだ。このアプローチは、同社の最近のテキストから動画へのプロジェクトである「Imagen Video」と「Phenaki」の2つを組み合わせたもの。どちらもまだ研究開発段階だが、最初のレンダリング画像は、このAIが我々の業界にとって画期的なものになる可能性を示している。
GoogleのAIでテキストからムービーを作成する方法とは?
最初に紹介するのは、「Phenaki」と呼ばれる技術だ。このモデルは、研究論文にあるように、いくつかの連続したテキストプロンプトを受け取り、それらの間につながりを作り、首尾一貫したビジュアルストーリーを合成することができる。見た目には、AIが映画の台本のように入力を読み取り、そのストーリーをどう絵にするかを決めているように見える(監督の仕事のように聞こえるだろうか)。例えば、次のような描写をPhenakiがどのように処理したかを見てみよう。「火星の水たまりを歩く宇宙飛行士を横から見たところ。火星でダンスをする宇宙飛行士、火星で犬を散歩させる宇宙飛行士、花火を見る宇宙飛行士とその犬。”

動いているところを見るには、Phenakiのウェブページにアクセスしていただきたい。この他にも、2分以上の動画がいくつか紹介されている。この動画では、AIがシームレスな移行をいかに見事に処理しているかに注目してほしい。上の例では、犬がいきなり出てくるわけではなない。本物の動物がするように、横からフレームに入ってくる。しかし、何も撮影する必要がなく、数秒のうちに制作されている。Phenakiの唯一の難点は、ビデオ解像度が128×128ピクセルしかないことだ。
Imagen Videoでアップスケール
そこで登場するのが、GoogleのAI研究プロジェクト第2弾。Imagen Videoは、ビデオ拡散モデルのカスケードを使用して、テキストプロンプトから高解像度のショートクリップを作成する生成システムだ。簡単に説明すると、テキストメモを受け取り、それをエンコードして、40×24の解像度、3fpsの小さな16フレームの動画を合成するところから始まる。ステップバイステップで、複数のディープラーニングモデルを使用して結果をアップグレードした後、通常のHDビデオ(1280×768)、最大5秒を生成することが可能だ。

あとはシンプルだ。Phenakiの長い複数シーケンスの動画を生成する能力と、Imagenの高解像度デタラメ化の力を組み合わせれば、近いうちにAIが映画全体を制作できるようになると言っていいかもしれない。とはいえ、グーグルの技術はまだ一般には公開されていない。同社の懸念のひとつは、こうした生成モデルが悪用されること–たとえば、偽のコンテンツや有害なコンテンツの作成に使われる可能性があることだ。そのため、研究者たちは、出力される映像素材をフィルタリングする方法を見つけるまで、ニューラルネットワークやソースコードを公開しないことにした。
ただし、Imagen & Phenakiの機能の一部は、AI Test Kitchenアプリに追加されることが約束された。このアプリでは、Googleの新しいAIプロジェクトについて学び、体験し、フィードバックを与えることができる。このアプリは現在、米国のユーザーしか利用できないが、誰でもここで興味を登録し、ウェイティングリストに載ることができる。
動画間生成技術「Gen-1」発表
動画を作るためのもうひとつの巨大なAIツールは、Stable Diffusionの立ち上げを支援したニューヨークのスタートアップ、Runwayが発表した(余談だが、これが何かわからない人は、このニューラルネットワークを使ってムードボードを作成する方法についてのガイドをチェックしてみてほしい)。最近、同社はGen-1という新しいモデルを発表した。これは、簡単なテキストプロンプトで、既存のビデオを視覚的にまったく新しいビデオに変換することができる。
その謳い文句の機能としては
- スタイライゼーション – 選択したスタイル(テキストに記載されているか、アプリケーションに特定のイメージを与えることによって)をビデオの各フレームに適用することができる。
- ストーリーボード – 単純に撮影したモックアップを完全にアニメーション化したレンダリングに変換する機能。
- マスク – ビデオ内の被写体を分離し、テキスト入力で修正する機能。
Gen-1もまだ公開されていないが、このフォームに記入すれば、誰でもアプリケーションへの早期アクセスをリクエストできる。私たちはすでに私たちのアプリケーションを待ち望んでおり、喜んでその機能をテストするつもりだ。
まとめ
このすべてが少し不気味に思えることがあったとしても、新しいAIツールは映像制作の分野に大きな影響を与えることができ、またそうなるだろう。これはもう止められないプロセスなので、私たちがこの技術を維持し、ワークフローに統合して創造性を増強するか、ボイコットして過去から抜け出せなくなるかどうかは、私たち次第なのだ。