
1年前、私たちは奇跡的なテキストから画像へのジェネレーターの台頭を目を見開いて見ていた。しかし、今やそれはホットニュースではない。ここ数カ月、技術競争はAIビデオジェネレーターに集中しており、当然ながらグーグルも乗り遅れるわけにはいかない。先週、同社の研究者はフルフレームレートのクリップを合成する試みを発表した。映画の父、リュミエール兄弟にちなんで命名された同社の映像拡散モデルは、驚くほど一貫した結果とリアルで一貫性のある動きを示している。残念ながら、まだ一般公開はされていない。Google Lumiereは、AIビデオのどんな未来を描いているのだろうか?
不思議なことに、Googleはすでに動画を生成するためのディープラーニングモデルをいくつか使って遊んでいる:「 Phenaki」と「Imagen Video」だ(これらについてはこちらで書いた)。どういうわけか、どちらも世に出ることはなく、現実のツールになるどころか研究論文にとどまった。同じ運命がGoogle Lumiereを待ち受けているのだろうか?時間が解決してくれるだろうが、発表された機能のいくつかはインディペンデント映画制作者にとって非常に有用に思えるので、そうでないことを祈りたい。
Google Lumiereの紹介
では、AI研究センターから生まれたばかりのこの新しい拡散モデルは何ができるのだろうか?公式発表やソーシャルメディア上のアナウンスによると、他の現代的なAIビデオジェネレーターが提供するものすべてだという。テキストの説明に基づいて5秒のクリップを作成したり、動画のスタイル化、静止画のアニメーション化、写真の選択された部分だけに動きをつけたりすることも含まれる。


さらに開発者は、インペインティングと呼ばれる特別な機能を導入し、動画クリエイターが既存のクリップの任意の部分をカスタマイズできるようにした(これについては後ほど詳しく説明する)。
Google Lumiereの何が特別なのか?
しかし、「インペインティング」機能以外は、グーグルの発表は画期的なニュースではない。他の利用可能なAIジェネレーター(RunwayやPikaなど)は、すでにこれらのツールをすべて提供している。さらに言えば、それらを試すことができる。それでも、元のツイートの下にあるコメントには、新しく発表されたAIモデルに対する大きな宣伝と関心が示されている。なぜか?
それは簡単だ。他の(すでに活躍している)ビデオジェネレーターは一貫性に苦戦しており、首尾一貫した動きを生成することはまだできない。一方、グーグル・ルミエールの開発者たちは、この問題を解決する新しい技術的アプローチを発見したと主張している。既存のモデルとは異なり、ルミエールはいわゆる時空間U-Netアーキテクチャを採用しており、これによりフルフレームレートの動画を一貫性のある1回のパスで作成することができる。これにより、出力はリアルで多様性があり、首尾一貫したものとなる。

Google Lumiereのウェブページで紹介されているショーケースは、かなり説得力があるように見えるだろう?しかし、私たち自身がこのモデルを試してみるまでは、完全には納得できないだろう。
ローカルでビデオを編集する
Google Lumiereの特別な機能のひとつに、マスクを使ってローカルでビデオを編集できるというものがある。すでに撮影されたクリップがあり、ポストで主人公の衣装を入れ替えたいと想像してほしい(私たちでも時々あることだ)。伝えられるところによると、この新しいAIソフトウェアはこのタスクを引き継ぎ、ほんの数秒で完了させることができる。必要なのは、選択した部分に何を入れたいかをテキストで記述するだけだ。
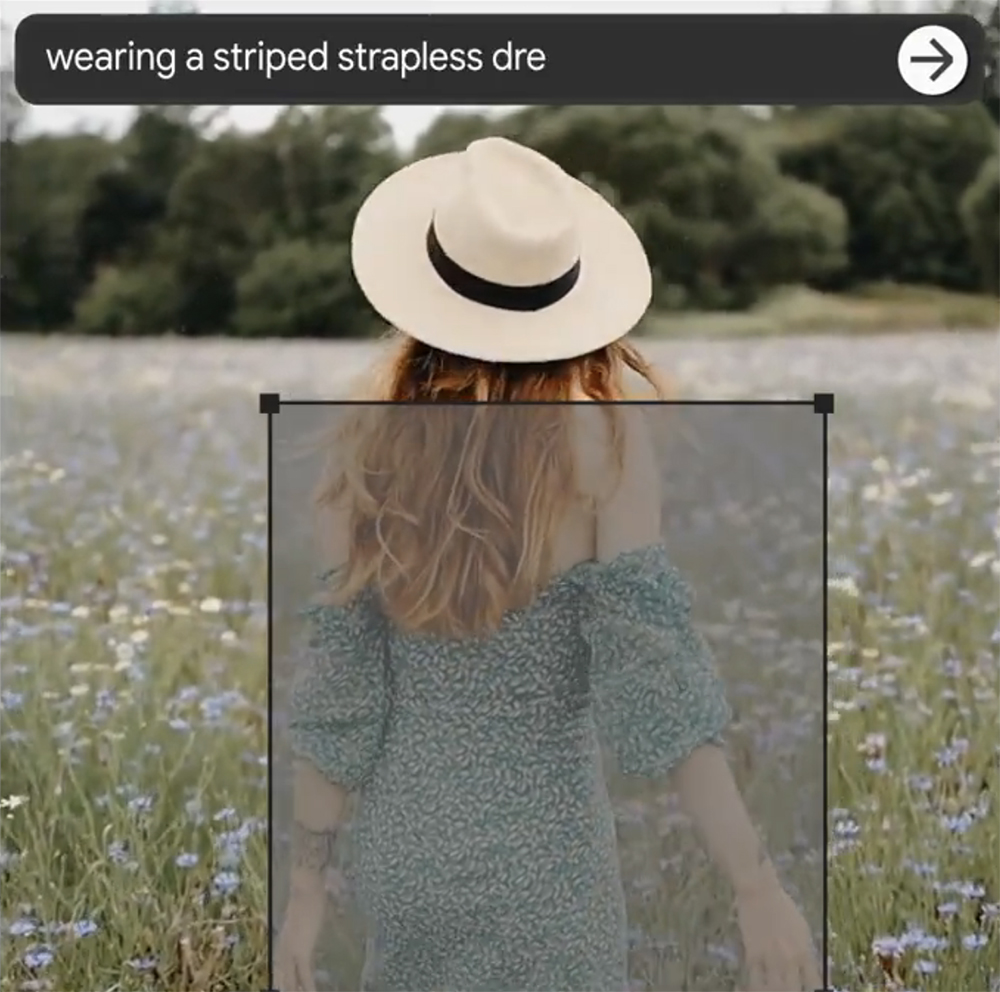
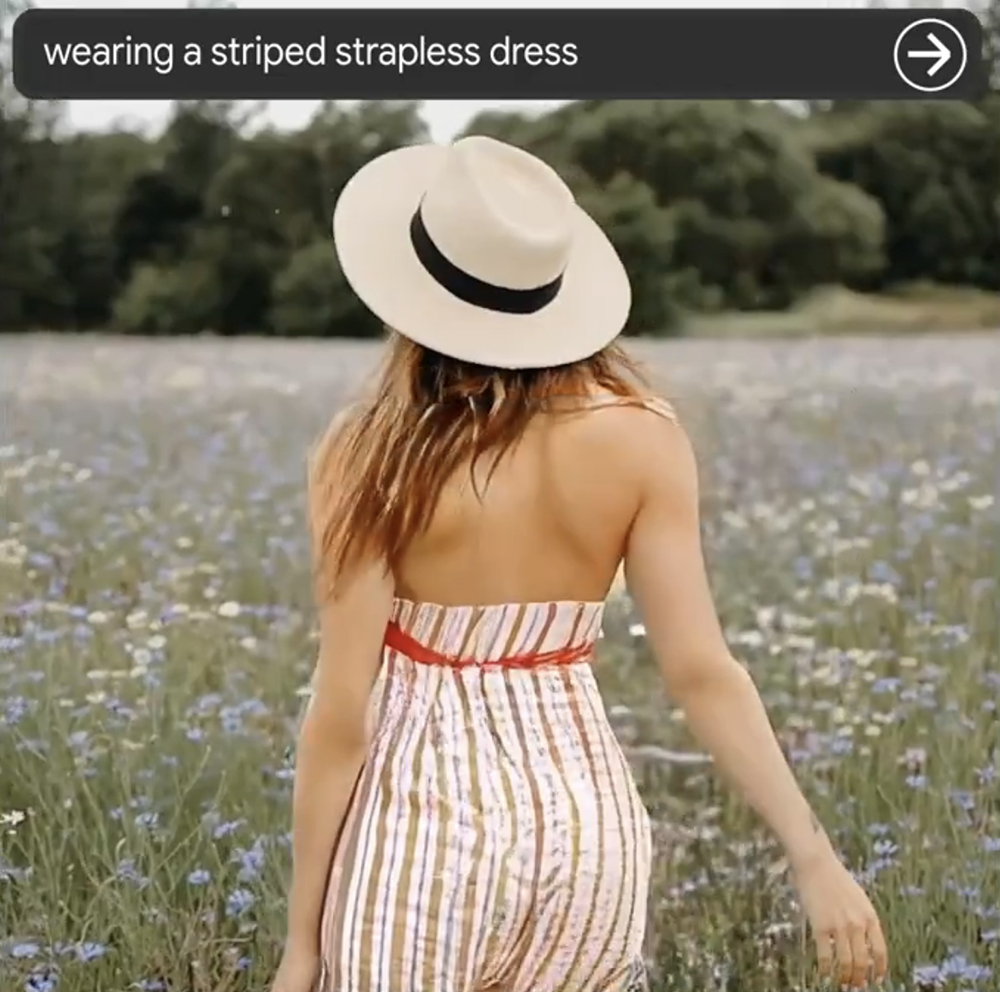
アドビは昨年の年次イベントで同様の機能を約束したが、AIビデオジェネレーターをワークフローに統合する最も便利な方法になるかもしれないと思う。
今のところは言葉だけ
Google Lumiereには確かに限界があるだろうが(例えば、複数のショットがあるシーンを合成できないなど)、テキストから動画生成への新たな一歩となる。しかし、今あるのは研究論文と開発者が発表したショーケースの一部だけである。このモデルがリリースされておらず、テストもできない以上、その能力を確認することも反証することもできない。
既存のAIビデオジェネレーターの実情に興味がある方は、こちらへどうぞ。ネタバレ注意:進化はしているが、すぐに私たちに取って代わることはないだろう。
Feature image source: Google Research








































