ChatGPTに代表される人工知能がすでにビデオ制作に影響を及ぼしているのは明白だ。ニューラルネットワークに基づく目に見えない小さな機能は、ポストプロダクションソフトウェアにも採用されつつある。しかし、サウンドの領域は、どういうわけか少し焦点から外れたままだ。しかし、技術の進歩は確実に浸透している。オーディオ用のさまざまなAIツールを見てみよう。
人工知能がいかに私たちの生活のあらゆる面に浸透しているかについて議論する必要はないだろう。時にはあまりに速く、憂慮すべき事態に思えることもある。グーグルのAIは今、あなたの脳信号に基づいて、あなたが聴く音楽を特定することができる。こちらの公式の研究論文を読むと、最初の2、3文を読んだだけで鳥肌が立つ。
時に不安になることもあるが、AI技術の発達は便利なツールをもたらし、我々の仕事を強化し、スピードアップするのに役立つ。この記事で “私たち “とは、自分たちでサウンドポストを作るインディーズ映画制作者のことであり、特にオーディオエンジニアのことを指している。
音声合成またはAI音声ジェネレーター
あなたのビデオプロジェクトで、吹き替えが必要になることはかなり多いのではないだろうか。私の意見では、機械が人間の口調や話し方を置き換えることはできないが、AIのパフォーマンスで十分な場合もある。例えば、プリビズやラフカット、人工音声が何らかの形で適切なストーリーにのみ必要な場合などだ。
AIボイスジェネレーターは、Siriが10年以上にわたって主導権を握ってきた世界では大きなニュースではないが、最新のものの中には実に印象的なものもある。LOVOを例にとってみよう。Gennyと呼ばれる同社の音声合成ツールは、最大25以上の感情を表現できる。若い女性の声で詩を読んでもらい、「疲れた」という感情を適用してそのリクエストを繰り返した。結果は印象的で、非常にリアルだった。
しかし、今回のテストで気づいたのは、Gennyのライブラリにあるスピーカーのうち、「感情的な」ボイスオーバーを提供するのは一部のスピーカーだけだということだ。そのため、標準的なナレーションにこだわるか、より感情的なボイスプレゼンターに選択を絞る必要がある。
また、LOVOは無料ではないが、さまざまな料金プランがあり、2週間の無料トライアルもある(Gennyでは20分のスピーチを作成できる)。しかし、Speechify(事前にテキストを入力し、選ばれたプレゼンターがどのように読み上げるかを聞くことができる)、新規ユーザーに10分間の生成ボイスオーバーを無料で提供するMurf.ai、追加データを提供することなく音声を異なる言語に変換できるResembleなど、市場には他にも数十のAIボイスジェネレーターが存在する。
最適な音楽を見つけるオーディオ用AIツール
AIは、あなたのプロジェクトに最適な音楽を見つけることもサポートしてくれるかもしれない。適切な楽曲を探してストック・ライブラリーを何時間もかけて探したことがある人なら、その苦労が現実のものであることを知っているはずだ。そのため、いくつかのプラットフォームでは、いわゆるAI搭載の検索を導入している。
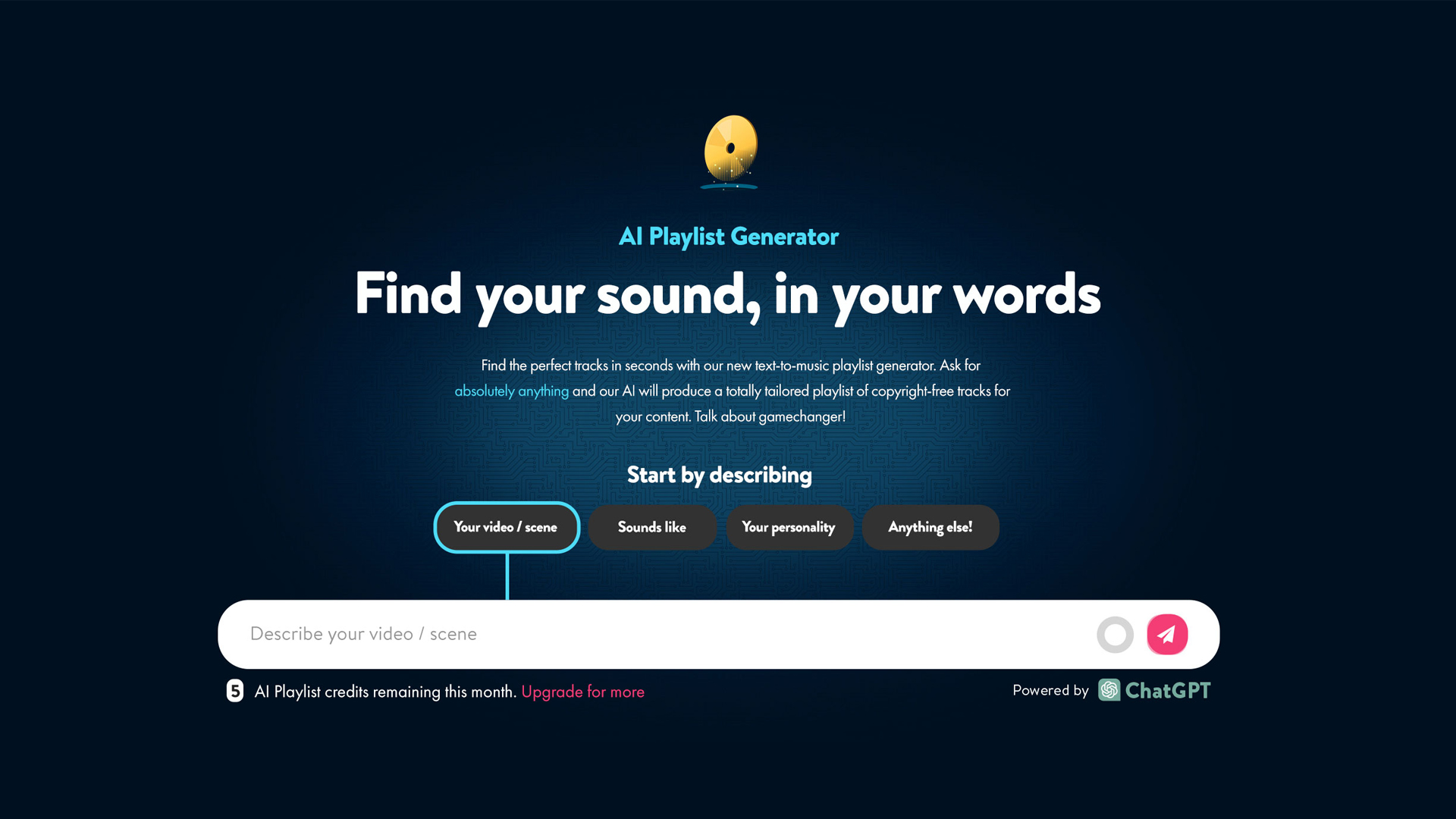
例えば、イギリスの無料音楽プラットフォームUppbeatは、少し前に、ユーザーが入力したテキストに基づいてAIがプレイリストを生成するという新機能を発表した。仕組みはいたってシンプルだ: ユーザーがビデオのシーンや音楽のイメージを説明すると、ほんの数秒で、プラットフォームがライブラリから適切なトラックをいくつか提案してくれるのだ。開発者が言うように、彼らのシステムは大規模な言語モデルChatGPTを使用しており、それが検索に組み込まれている。
あなたのビデオプロジェクトでこの機能を使用する方法については、こちらをご覧ください。
AIの助けを借りて音楽トラック全体を作成する
ストック・ミュージックに耐えられなくなったとき(誰にでもたまにあることだと思うが)、ニューラルネットワークはあなたのために何か違うものを作り出すことができる。現在、(何百もの小規模なものと並んで)2つの大きなAI音楽ジェネレーターがあり、ユーザーを奪い合っている。ひとつはGoogleのMusicLM、もうひとつはMetaのMusicGenだ。
どちらも実験的なAIツールであり、テキスト記述からメロディーを生成することができる。しかし、グーグルが新しいジェネレイティブ・ソフトウェアを試すためにAIテスト・キッチンに参加させているのに対し(ここでサインアップして招待を待つことができる)、メタのプロジェクトは完全にオープンソースである。詳しくはこちらで書いている。
MusicLM. Image source: Google 
Trying out MusicGen by Meta. Image source: HuggingFace
では、ミュージックジェネレーターはどのように機能するのか?機械学習モデルに任意のテキスト記述(または/または参照トラック)を与えると、メロディが返ってくる。例えば、「歪んだギター・リフに支えられた落ち着いたバイオリンのメロディ」や、「フレンズのイントロをダークメタル風にひねったバージョン」をAIに求めることができる。グーグルによると、MusicLMは24kHzで音楽を生成し、それは数分間一貫している。一方、MusicGenは出力トラックを15秒に制限している。
後者は今すぐHugging Face Spaceで試すことができる。私たちのテスト結果はかなりぎこちなく、実際のプロジェクトで使うにはまだ早かったが、ニューラルネットワークは学習速度は速く、来年にはAIが生成する音楽が実現するかもしれない。
オーディオ用AIによるサウンドエフェクト
MusicGenのリリース後、Metaは同様のAIを搭載したサウンドエフェクト用ソフトウェアも発表した。これはAudioGenと呼ばれ、同じ原理で動作する。探しているサウンドを記述し、ニューラルネットワークに魔法をかけさせる。
開発者はAudioGenを公開されている効果音で訓練し、音響シーンをテキストで説明すると、それにマッチした5秒間の音声を生成する。これはオープンソース・プロジェクトでもあるので、Hugging Faceでモデルを試すこともできるし、ここからダウンロードして調整し、さらに訓練することもできる。
AudioGenの個人的な初体験は、今のところ厄介なものだった。このモデルは言葉を完璧に理解し、一致する音を見つけようと最善を尽くすが、全体的なトラック構成は一貫性がなく、リアルに感じられない。とはいえ、これは驚くべき開発であり、AIがサウンドライブラリのまともな代替手段を提供するまで、そう時間はかからないだろう。
おそらく覚えていると思うが、アドビも同様のSFXジェネレイティブ機能を、近々発表予定の「Firefly for video」プロジェクトで発表している。私たちはその機能を目の当たりにすることになるだろう。
音声ポストプロダクションと音声品質の向上
アドビといえば、昨年はオーディオ用AIツールを含む、人工知能を使ったさまざまなアプリケーションの開発に力を入れていた。例えば、同社のAIオーディオエンハンサー(Adobe Podcastの一部)は、低品質の音声録音をプロのスタジオで録音したかのようにすることができる。試してみたい方はこちら。
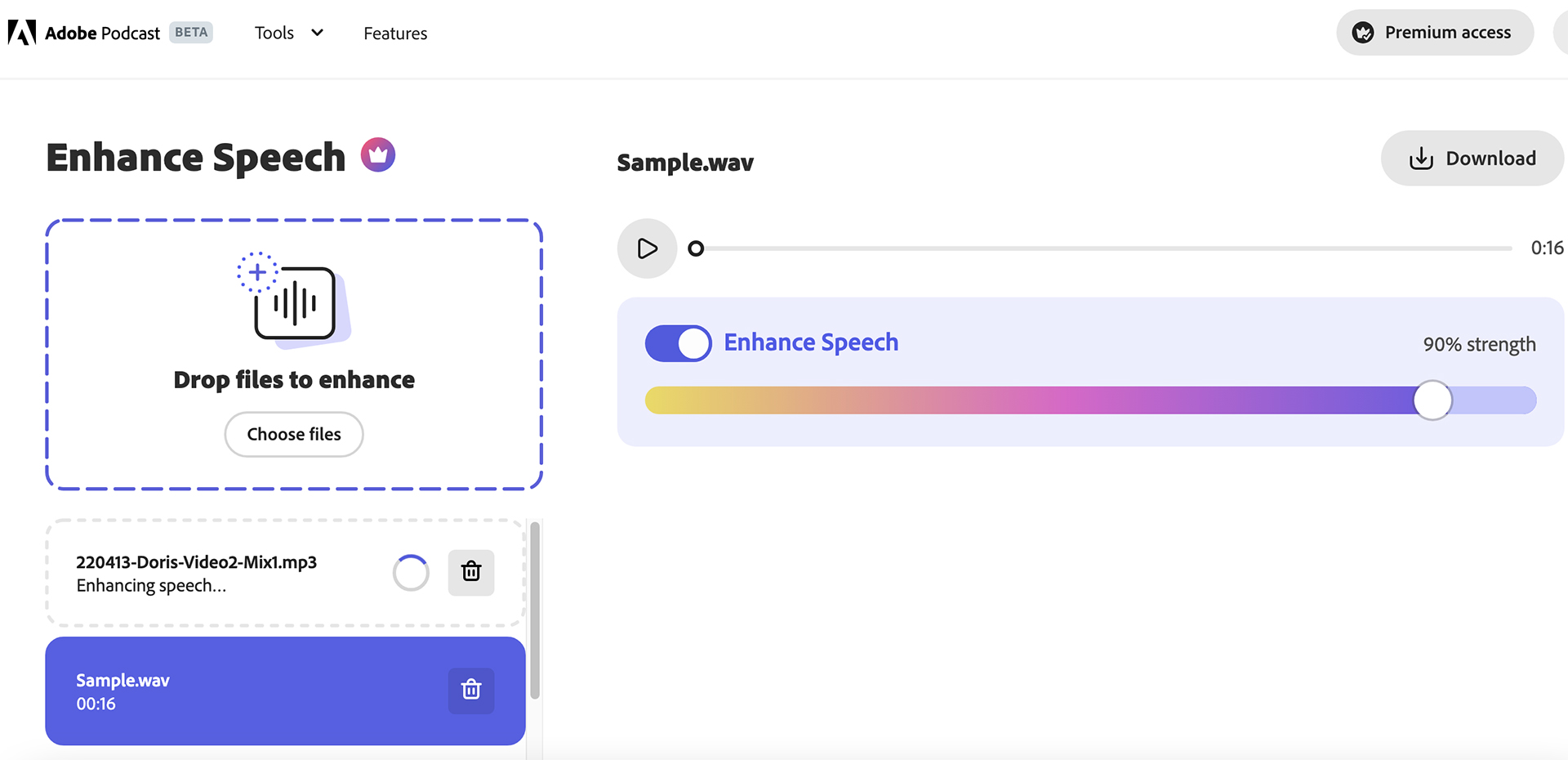
オーディオエンハンサーは、すべての邪魔なバックグラウンドノイズを除去し、周波数を洗練させるために音を調整し、録音に全体的なプロの品質を与える。これは、特に騒がしい場所でインタビューを録音した場合、発言のために手元にスマートフォンしかなかった場合、または不適切にレベル調整されたオーディオファイルを保存したい場合に最適なスピーチエンハンサーだ。ただし、音声にしか機能しないので、例えば音楽の音質向上には役立たない。
Adobeのサブスクリプションを持っていない場合は、このタスクのための他の類似のAIツールがある。例えば、AI|Cousticsは無料で使用でき、.mp3、.wav、.m4aの音声ファイルに対応している。
音声用AIツールで音声トラックと音楽トラックを分ける
このオーバービューで最後に紹介したい便利なオーディオ・ツールは、LALAL.aiだ。カシオペアと呼ばれる彼らのAIは、ユーザーが音声とサウンドトラックを分離することを可能にする。開発者によると、ニューラルネットワークはステムセパレーションと呼ばれる技術を使って、ボーカルと音楽を区別する。そうすることで、バックグラウンドのメロディーを異なる楽器に分解することもでき、録音の任意の部分を分離して編集することができる。
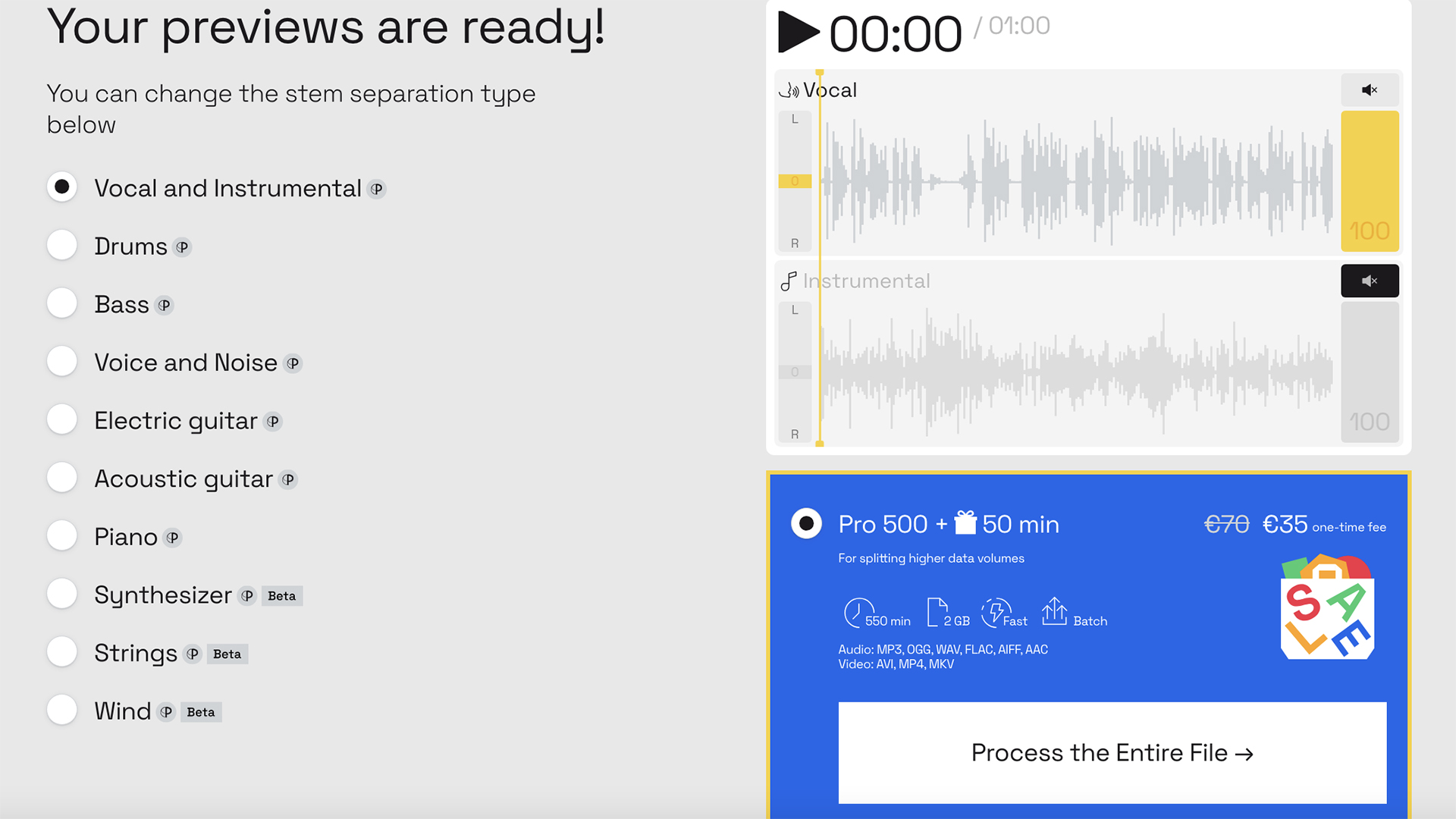
なぜそのようなツールが必要なのか?いくつかの理由がある。アーカイブ映像を持っていて、その中からボイスオーバーの部分だけが欲しいのかもしれない。また、YouTubeのパロディビデオで、好きな映画やシリーズの特定のオーディオトラックが必要な場合もあるだろう。シンプルなカラオケのバッキングプレートの作成も、LALAL.aiが提供する良い例だ。
LALAL.aiはサブスクリプションプランなしで試すことができるが、10分間の録音に限られる。それ以降は、抽出したい音声の長さに応じて課金される。
完全にゼロコストのツールが必要な場合は、Vocal Removerをご覧ください。このアプリケーションは競合製品に比べるとパワーは劣るが(AIを使って音楽から音声を分離することしかできない)、仕事はしてくれる。
リストはまだまだ続く
この記事で少なくとも10種類のオーディオ用AIツールを紹介したが、まだ表面しか見ていないような気がする。この分野にはエキサイティングな研究がたくさんあり、毎日新しいアプリケーションが登場している。お気に入りの本や小説のSpotifyプレイリストをAIが作成するMuzifyをご存知だろうか?AIがテイラー・スウィフトのようなお気に入りのアーティストの音楽カバーを作成するVoicifyはどうだろう?
Feature image source: created with Midjourney for CineD.