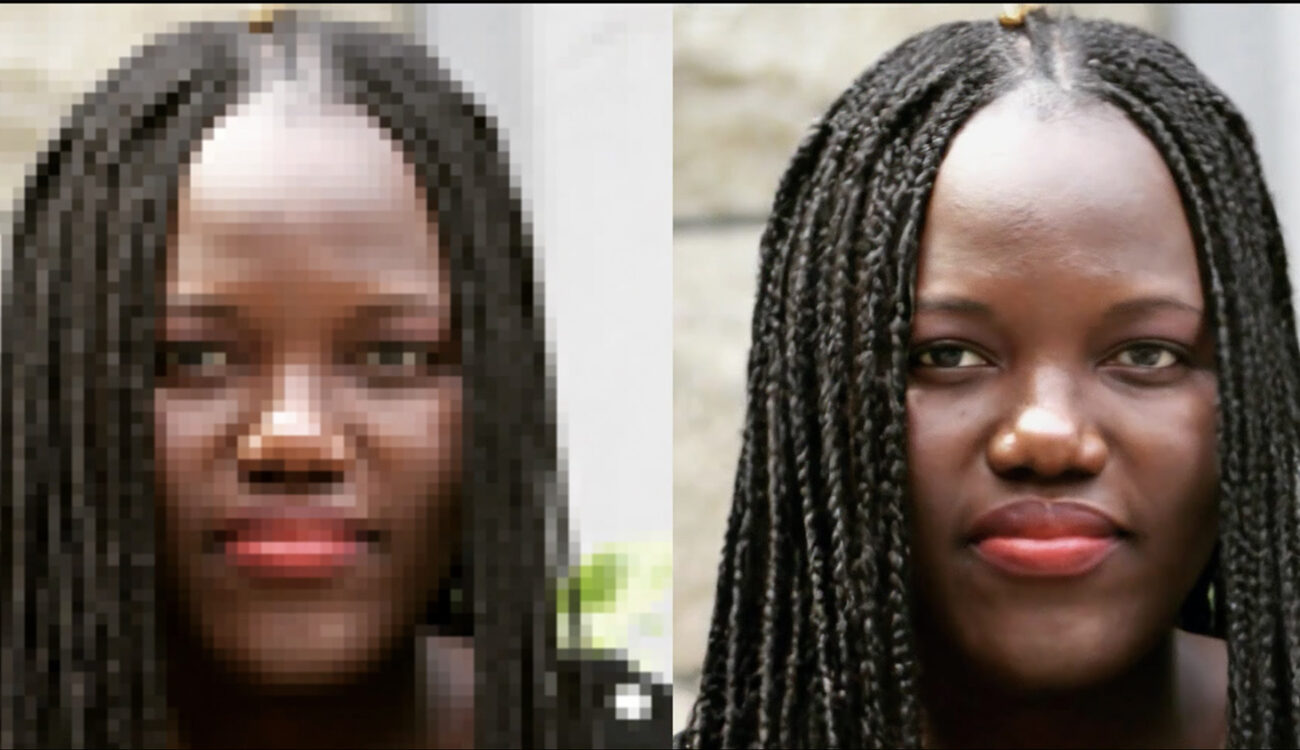
SFや刑事ドラマに出てくる「解像度補完」機能がもうすぐ現実になるかもしれない。GoogleのBrain Teamの研究者が、Google AI Blogに「High Fidelity Image Generation Using Diffusion Models」という記事を掲載した。この論文では、画像のノイズをニューラルネットワークの学習基盤として利用することで、画像を4〜8倍にアップスケールすることができるとしている。
リサーチサイエンティストのJonathan Ho氏とソフトウェアエンジニアのChitwan Saharia氏が発表したGoogle AI Blogの記事では、彼らのアプローチについて詳しく説明されている。このコンセプトは2015年に初めて紹介されたが、棚上げされていた。しかし、今回再び注目されることになった。概念的には、DaVinci Resolveのスーパースケール機能やNvidiaのDLSS解像度向上機能と変わりないものだ。しかし、内部は全く別の話で、まだ初期の開発段階だが、この新しいAIフォトアップスケーリングのアプローチは、信じられないような効果につながる可能性がある。映像クリエーターだけでなく、写真家やゲーム開発者にとっても同様だ。
プロセス
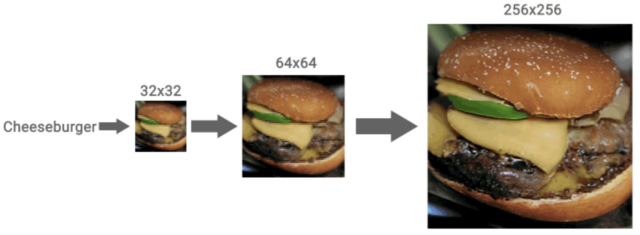
チームはまず、SR3(Super-Resolution via Repeated Refinement)と呼ばれる、純粋なノイズを用いて低解像度の入力から高解像度の画像を構築する超解像拡散モデルを使用した。このモデルは、画像の破損プロセスを用いて学習される。

その仕組みは、高解像度の画像にノイズを加え、純粋なノイズだけが残るようにしている。その後、ニューラルネットワークが学習して、最初の画像を復元するためにプロセスを逆転させる。最後に、この学習したニューラルネットワークを64×64ピクセルの画像に使用して、スーパースケールバージョンを作成する。次に、このプロセスをさらに改善するためにスタックで使用した。64×64→256×256のモデルと、256×256→1024×1024のモデルを重ねることで、画期的なアップスケーリングの結果を得ることができたという。

Alchさらに強化されたアプローチ
更に、最初のSR3プロセスを超えて、Cascaded Diffusion Models(CDM)を使用した。これらのモデルは、ImageNetのデータで学習され、高解像度の自然画像を生成する。視覚的物体認識ソフトウェアの研究用に設計された大規模なビジュアルデータベースのImageNetのデータを使用することで、SR3アプローチをさらに強化するアップスケーリングモデルを作成することができた。
実世界での応用
SR3とCMDモデルを使って画像をアップスケールすることで、高解像度画像の必要性を減らすための最先端のアプローチを生み出した。残念ながら、この新しいAIによる写真のアップスケール処理は、まだ実用途のレベルではない。しかし、このようなテクノロジーが登場することは、今後の映像制作にも大きく影響するだろう。
このアプローチは、セキュリティカメラに最適だろう。また、画像だけでなく、ビデオやコンピュータグラフィックスなどのポストプロダクションパイプラインにも利用できると思われる。NvidiaはすでにDLSS技術でこれを実現している。これは、サブHD品質のレンダリングから4Kを出力し、GPUへの負担を軽減するものだ。将来のカメラでは、色再現性とダイナミックレンジに優れた1080pの画像を記録し、ポストで4Kにアップスケールすることも可能だ。Netflixの4K義務化は、いつか過去のものになるかもしれない。ただし、それは何十年も先のことかもしれないが。
現段階では、まだSFのレベルかもしれない。








































